如何利用人工智能基础模型加速科学发现?
本文翻译自微软博客:From forecasting storms to designing molecules: How new AI foundation models can speed up scientific discovery
人类一直在寻找能够解释宇宙现象并预测未来的模式(pattern)。“晚霞行千里,朝霞不出门。”就是一句用于预测天气的谚语。
人工智能的一个强大能力就是发现数据中的规律与模式,并做出预测。现在,微软的研究员们正在努力将利用了前沿人工智能技术的“基础模型”应用于科学发现。与那些专门针对特定任务设计的模型不同,基础模型经过了多领域数据的训练,能够在众多任务中展现出卓越的性能。相比传统方法,它们不仅能够大幅提升生成答案的效率,还能帮助解决更复杂的科学问题。
正因为此,人工智能在材料科学、气候科学以及医疗健康和生命科学等领域具有广阔的应用前景。专家表示,针对这些领域定制的基础模型将极大加速科学发现的进程,促进领域科学家更快地实现创新成果,例如药物研发、新材料发现和提高天气预报的准确性,同时基础模型还能加深人们对原子、人体或者地球的认识。目前,微软研究院正在开发这些模型,其中第一个天气预测模型 Aurora 已经发布。
“作为工具箱中的工具之一,人工智能能够为你提供更智能的支持。”微软研究院科学智能中心(AI for Science)副总监 Bonnie Kruft 说,“我们希望开发专门针对科学领域的模型,而不是针对语言的模型。这一重大机遇,将会把传统基于人类语言的大模型推向全新的范式,利用数学和分子模拟打造更强大的科学发现模型。”

微软研究院科学智能中心副总监 Bonnie Kruft
近年来人工智能的进步使人们能够通过简单的对话提示就可以策划派对、生成图形演示文稿,或者获取错过会议的即时摘要。这些功能的实现都得益于大语言模型(LLMs)。基于海量文本数据进行训练,这类基础模型能够执行多种与语言相关的任务。如今,微软的研究员们正在探索如何利用类似的人工智能架构和方法来推动科学发现的进一步发展。
“大语言模型有两个非常有用的特性。首先,它能够生成并理解人类的语言,这为复杂的技术提供了一个良好的人机交互界面。其次,大语言模型可以作为一个有效的推理引擎,我想这对许多人来说都是一个惊喜,因为它将可以在科学发现中发挥巨大作用。”微软技术院士、微软研究院科学智能中心负责人 Chris Bishop 在今年的 Microsoft Research Forum 主题演讲中说道。
曾经,人工智能的科研人员认为,那些专为特定任务训练的模型会比像大语言模型这样更大的通用模型表现更好,例如那些能够在国际象棋或双陆棋中获胜(但不能两者兼顾)的模型,或者那些能够翻译语言或转录语音(但不能两者兼顾)的模型。然而,结果却恰恰相反,人们没有必要为处理法律问题、进行物理研究或研究莎士比亚作品分别训练模型,因为一个大型通用模型就能在不同学科和任务中获得出色的表现。现在,研究员们正在研究基础模型是否也能在科学领域实现类似的结果。
通常,科学发现的过程包括提出假设、进行测试,然后多次调整直至找到解决方案或重新开始,这是一个不断排除无效选项的过程。相比之下,基础模型则通过构建而非排除改变了这一传统模式。科学家们可以为这些基础模型设定参数,例如他们期望的特性,然后模型就可以预测出可能有效的分子组合。与其大海捞针,不如让模型直接指导如何制造出“针”来。
另外,这些基础模型还能够理解自然语言,便于科学家们撰写提示词。例如,在寻找一种新材料时,科学家可以具体说明他们需要的分子必须是稳定的(不会分解的)、非磁性的、不导电的,以及非稀有或非成本高昂的。
尽管大语言模型通常是在文本数据(单词)上进行训练,但微软的研究员们开发的基础模型则是在科学的“语言”上训练的,旨在推动科学发现。这不仅包括科学相关的书籍和研究论文,还有大量求解物理或化学方程所产生的数据。
将天气和污染预测提升到新水平的 Aurora 模型,是通过学习地球大气语言来训练的。MatterGen 模型能够根据给定条件生成新材料,MatterSim 模型则可以预测这些新材料的行为,它们都是基于分子语言进行训练的。由微软研究院与全球健康药物研发中心(GHDDI)合作开发的 TamGen 模型,可用于设计治疗结核病和新冠等疾病的新药和蛋白质抑制剂。
正如不同的食物适合不同的烹饪方法——有的适合油炸,有的适合蒸煮,还有的适合烘焙,不同的科学问题也需要不同的人工智能技术。许多近期开发的人工智能模型属于生成式模型,它们能够根据自然语言生成答案和图像。而另一些模型则是仿真器,可以预测物体的属性或行为。
然而,这些基础模型中的每一个都具有广泛的应用范围,材料模型不只是试图发现一种材料,而是会发现多种多样的材料;大气模型不是只预测降雨,还能预测污染等其他现象。这种多功能性是将一个人工智能模型定义为基础模型的关键特征。最终目标是将多个模型集成在一起,创建更通用的模型,因为在其他领域,更通用且更多样化的模型已经超越了单一功能的模型。
MatterGen:探索新材料发现新材料看似是一个细分的专业领域,但实际上它是囊括了广泛子领域的研发的重点之一,因为材料的种类繁多,包括合金、陶瓷、聚合物、复合材料、半导体等,而且原子组合成新分子的可能方式数以十亿计。新材料的开发对于减少碳排放、寻找对环境或健康无害的替代材料至关重要。
微软研究院的 MatterGen 基础模型“能够直接生成符合你设计条件的材料。”微软剑桥研究院的首席研究员谢天表示。科学家们不仅可以告诉 MatterGen 他们想要创造的材料类型,还能指定所需的机械、电气、磁性和其他属性。“它给材料科学家们提供了一种方法,为他们想要设计的材料提出更好的假设。”谢天说。

微软剑桥研究院首席研究员谢天
“相比以往的方法,这取得了重大进步,因为人工智能在生成材料方面的效率,比筛选数百万种潜在组合以满足科学家标准的方法高出三到五个数量级。”谢天说,“MatterGen 基于科学家设定的标准直接构建解决方案,而不是从所有可能性出发,通过反复筛选直到找到少数符合科学家标准的组合。这远比在实验室中通过反复试验来创造新材料要高效和经济,当然合成新材料候选物所需的实验室工作仍是必不可少的。”
MatterGen 属于扩散模型,这是一种用于图像创作工具的人工智能架构。不同的是,MatterGen 用于生成新材料。然而,要训练一个基础模型,人类数十年甚至几个世纪以来积累的实验数据都远远不够,但由于物理和化学等科学领域遵循既定的数学方程,所以通过多次计算这些方程就可以产生所需的大量高质量训练数据。研究团队利用密度泛函理论这一量子力学方法通过高性能计算,为 MatterGen 生成了约60万个结构的训练数据。
现在,微软的 MatterGen 研究团队正与合作伙伴携手验证其生成的一些材料。下一步,团队还计划探索聚合物的回收利用,以及开发可用于碳捕获的金属-有机框架。“目前,我们主要聚焦于无机材料,但我们期望未来能够将研究扩展到更加复杂的材料领域。”谢天表示。
MatterSim:预测新材料的行为尽管有人工智能的帮助,但创造新材料的过程依然充满挑战。与 MatterGen 常常配套使用的 MatterSim 能够模拟并预测新材料分子的行为属性。如果模拟结果未能达到科学家的预期,那么他们可以通过 MatterGen 进行迭代调整,就像微调 Microsoft Copilot 提示词一样不断优化输入,直至满足科学家的需求。然而,与 MatterGen 不同的是,MatterSim 并不是生成式人工智能而是一个仿真器,它能够确定分子在不同温度和压力条件下的属性和行为。
MatterSim 采用了 Graphormer 架构,该架构基于 Transformers 理念,类似于大语言模型通过拆分单词或句子来学习预测句子中的下一个单词,只不过 MatterSim 是微软研究院专为材料行为和属性预测而开发的模型。“MatterSim 是基于原子语言训练而成的。”微软研究院科学智能中心首席研究员陆子恒说,“预测材料的行为对化学家至关重要。更重要的是,模型从整个元素周期表中学习,掌握了原子的语言。分子在嵌入空间中呈现怎样的形态?如何将分子的结构转换为机器可理解的向量?这是 MatterSim 除了预测材料属性能力之外最重要的事情。”

微软研究院科学智能中心首席研究员陆子恒
MatterSim 还采用了主动学习的方法,这与学生备考的学习方式相似。当模型接收到新数据时,它会自己判断对数据的掌握程度。如果掌握程度较低,那么这些数据就会进入模拟中重新训练模型,就像学生学习他们尚未掌握的知识点一样,而不是学习那些已经熟悉的内容。
由于关于分子行为的数据非常有限,所以研究团队采用了量子力学的计算方法来生成合成数据,这与 MatterGen 的处理方式相似。其结果的准确性是之前模型的十倍,“因为我们能够生成数据来覆盖前所未有的材料空间,这使得模型非常精确。”陆子恒说。
目前,MatterSim 专注于无机材料,但未来会扩展至其他类型。“MatterSim 是一个特定领域的基础模型。人工智能科学领域的科研人员正向一个统一的大型基础模型迈进,这个模型能够理解整个科学语言,包括分子、生物分子、DNA、材料、蛋白质,所有这些以后都将统一,但就目前的 MatterSim 而言,我们统一的是整个元素周期表。”陆子恒说。
Aurora:革新大气预测长期以来,计算机对天气预报至关重要,它通过解析物理或流体动力学方程来模拟大气系统。“如今,人工智能和基础模型带来了前所未有的新机遇。”微软研究院科学智能中心首席研究员 Paris Perdikaris 表示,“我们应该走出去,尽可能地观察世界、收集数据,然后训练一个人工智能系统来处理这些数据,从中提取模式,并帮助人们预测天气等。”
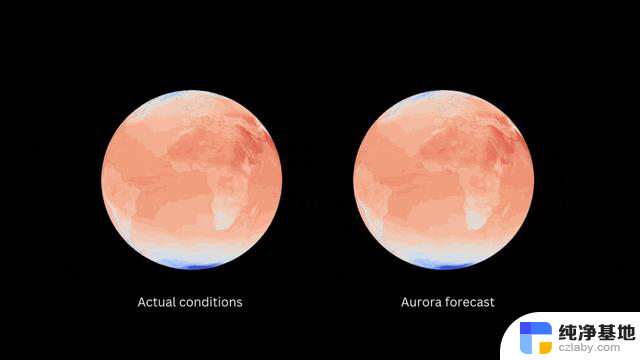
右边的球体显示的是 Aurora 的天气预报,左边的球体显示的是测量到的实际情况
“人工智能的显著优势在于一旦训练完成,它就无需依赖庞大的计算资源。目前,使用超级计算机全天候运行来生成10天的天气预报大约需要两个小时。”Perdikaris 说,“相比之下,微软的大气基础模型 Aurora 能在几秒钟内完成同样的任务,却仅需一台配备 GPU 的台式电脑。人工智能方法带来了计算效率的提升和预测成本的降低。”
Aurora 还提高了准确性,因为它不仅使用了基于物理模型的数据,还融合了来自卫星、气象站和其他来源的真实世界数据,“这些数据能更真实地反映现实情况。” Perdikaris 说,“由于能够接触到更多样化的信息源,Aurora 可以将它们融合起来,从而产生比现有的传统模拟工具更为精准的预测。”
Aurora 是一个大型神经网络,一种视觉 Transformer,它经过了1.2PB数据的训练——这大约是互联网上所有文本信息总量的十倍。“然而,与描述整个地球系统所需的数据量相比,这只是冰山一角。”Perdikaris 指出。

微软研究院科学智能中心首席研究员 Paris Perdikaris
针对三大常见天气问题:未来十分钟内这里是否会下雨?未来10天内全球天气将如何变化?未来数月甚至数年的天气情况是怎样的?这在过去通常需要依赖不同的预测模型来解答。而 Aurora 及其未来的扩展模型将会使用同一个模型来回答所有这些问题。
Aurora 最初是基于天气数据进行训练的,但通过结合大气化学数据进一步微调后,该模型还能够预测污染水平。“我们最初的假设是利用模型从天气中学到知识,并尝试将其迁移到由不同物理定律支配的新任务中,例如大气化学,然后观察其效果。”Perdikaris 说,“令人惊讶的是,这种方法不仅可行,而且初步结果让人相当惊喜。”人工智能的优势在污染预测中更加明显,因为污染预测的成本是天气预测的十倍。
让科学发现触手可及陆子恒指出,这些人工智能基础模型能够极大地激发学生对科学的兴趣。在他求学时,他需要在白板上写出方程来理解抽象的科学概念,“但现在有了这些模拟工具,我们用电脑就可以进行统计分析。你可以直接在屏幕上实时观察分子和材料的反应与行为,对实际发生的现象有一个直观的感受,而不仅仅是看着纸上的方程。”
微软的科学基础模型全部是在微软 Azure 云平台上从零开始构建的。微软计划提供这些模型的早期版本,以推动科学发现的普及,并从社区收集反馈。“这些反馈将用于识别实际应用场景,以进一步指导和完善模型的未来版本。”Kruft 说。
基础模型有望彻底改变人们的日常生活并给行业带来变革。通过加快科学发现的步伐,基础模型不仅有潜力推动医学和材料等领域的快速发展,而且还提供了对原子、分子和蛋白质等复杂系统的更深入洞察,Kruft 说,这些深刻的洞察将为众多行业开辟广阔的商业机遇。
相关链接:
Aurora:
https://microsoft.github.io/aurora/intro.html
MatterGen:
https://m.microsoft.com/en-us/research/blog/mattergen-property-guided-materials-design/
MatterSim:
https://m.microsoft.com/en-us/research/blog/mattersim-a-deep-learning-model-for-materials-under-real-world-conditions/
TamGen:
https://m.microsoft.com/en-us/research/publication/target-aware-molecule-generation-for-drug-design-using-a-chemical-language-model/
Graphormer:
https://m.microsoft.com/en-us/research/project/graphormer/