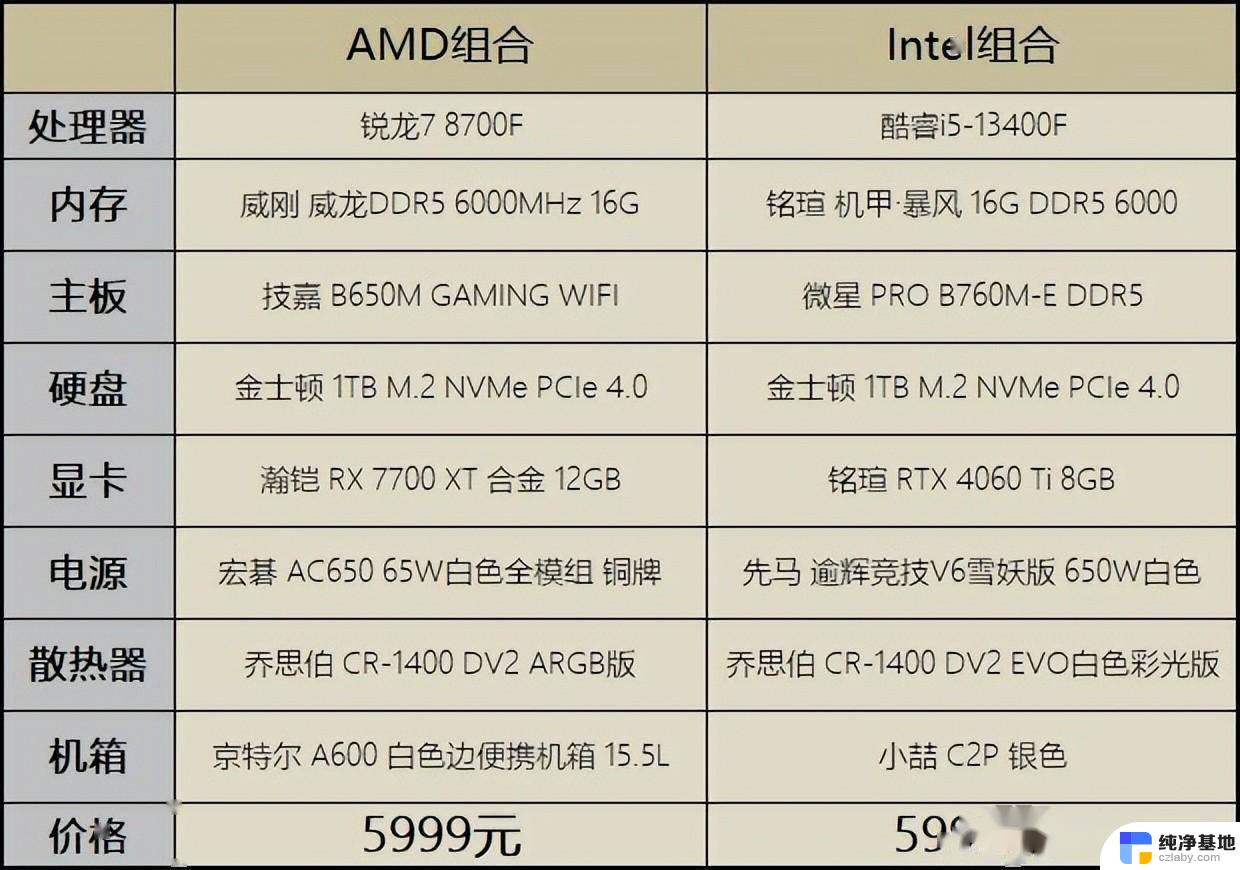
AMD Zen 5架构详细资料揭秘:全面解析两款新SoC

Zen 5架构的设计目标是提升单线程和2线程的性能,并为未来计算核心架构奠定新的基础,并为AVX512运算提供完整的512位数据位宽以提升吞吐量并提高AI运算性能。而平台方面,新架构包含Zen 5和Zen 5c两种针对不同方向优化的核心,虽然现在Zen 5处理器都是用台积电4nm,但未来会有3nm的版本,Zen 5支持可配置的FP512/FP256数据,并新增了ISA功能指令集。
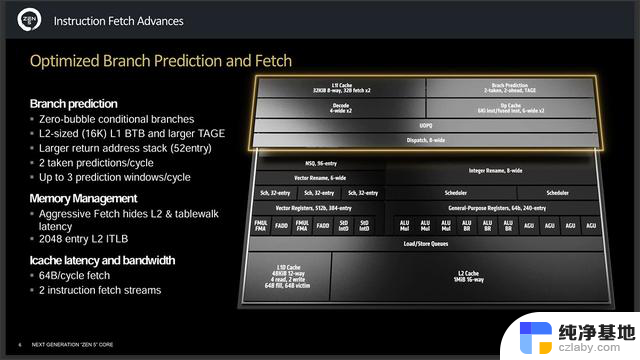
Zen 5直接升级成双管道预取和解码,优化分支预测与预取Zero-bubble分支,L1/L2分支目标缓冲区从上代的1.5K/7K大幅扩大至16K/8K,目标地址生成引擎也更大,返回地址堆栈现在扩大到52个条目,这些改动可提高处理器的分支预测准确性,减少分支重定向的开销,从而提升性能,现在每周期最多可采取2次预测,最多3个预测窗口。
内存管理采取了激进的取指隐藏了L2和表遍历延迟,L2指令地址转换缓存扩大到2048个条目。缓存延迟与带宽方面现在每周期64字节的取指,并有两个指令取指流。这些改动能让处理器够快速地从缓存中获取指令,并且支持多个指令同时进行取指,从而提高了处理器的吞吐量和效率。
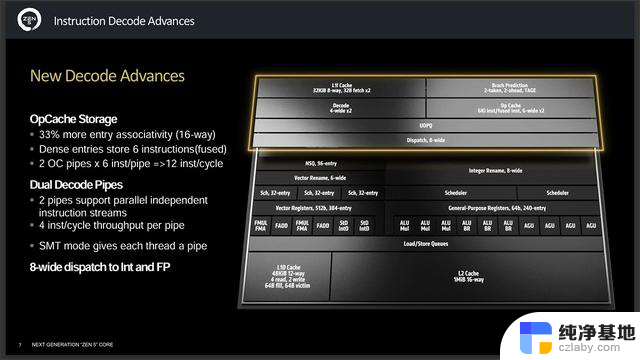
解码部分同样升级成双管道,两个管道支持独立的并行指令流,每个管道每周期处理4条指令,在SMT模式则为每个线程提供一根管道,在工作分配上,有8-wide派遣到整数和浮点运算执行单元。Op Cache方面,条目关联性从12-way增加到16-way,密集型条目存储6个指令,由于采用双管道设计所以每周期一共可存储12个指令。
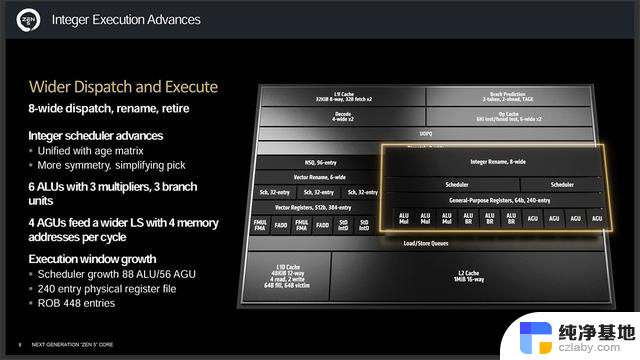
整数执行单元加宽了指令分派和执行通道,分配和引退从以往Zen架构的每时钟周期6条指令增加到8条,整数调度听过age matrix同一可以更堆成并简化挑选。
以往的旧Zen架构整数执行单元包括4个ALU和3个AGU,而Zen 5则增加到6个ALU和4个AGU,而这6个ALU包含3个多乘法器和3个分支单元,4个AGU可每周期处理4个内存地址。执行窗口也显著增长,调度器增长到88 ALU和56 AGU,并配备240条目的物理寄存器,在更复杂的计算工作负载下会有更好表现。
此外核心缓冲区从320条目增加到448条目,以更好地处理更广的调度和执行所产生的更多的未命中。

浮点执行单元获得重大更新,AMD自上代Zen 4开始支持AVX-512指令集,但那是使用256位SIMD用两个时钟周期来执行AVX-512指令的,而Zen 5则可提供完整的512位数据位宽。新的执行单元拥有更高的带宽与更低的延迟,拥有4条执行管线,2条LS/整数寄存器管线,每周期可执行2条512b的加载和1条512b存储,并配备2周期延迟的FADD。
执行窗口也变得更大,NSQ伴随8-wide派遣而有所增加,从64增加到96;调度器数量从2个增加到3个;物理寄存器从192翻倍到384;ROB/退休队列从320增加到448。这些改动让CPU可处理更多浮点指令,在CPU执行一些AI模型时,能够显著提高反应速度与效能,面对未来各种AI应用。

缓存方面,一级数据缓存容量从32KB增加到48KB,宽度也从8路增加到12路,4条L/S管道每周期4次读取2次写入;4条整数装载管道可以配对到2条浮点管道;每周期2条储存提交;与L2缓存的通信位宽上下行均从32B翻倍到34B,让L2带宽直接翻倍。DTLB数据转换旁路缓存也跟随增长,L1从72条目增加到96条目,L2则从3072增长到4096。一级缓存与浮点单元的最大带宽直接比上代翻倍,改善了数据预取的效率。

以上就是Zen 5架构的改进更新重点,改进方向大体可归纳为:每周期可执行更多指令;更宽的调度和执行单元;数据缓存带宽翻倍;更强的AI加速性能。

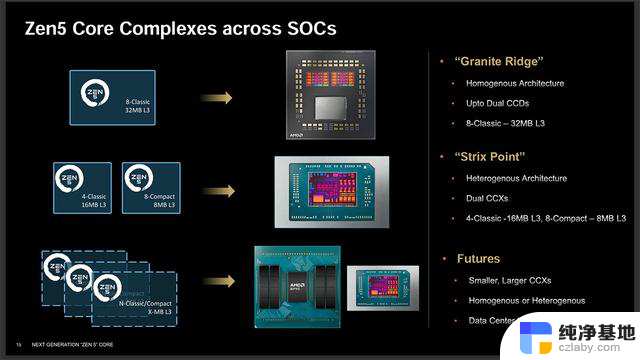
新架构包含Zen 5和Zen 5c两种采用同架构,但针对不同方向侧重优化而设计不同的核心。Zen 5是针对单线程性能优化的核心,目标是更高的时钟频率,每核心更大的L3缓存,因此Zen 5核心会更为耗电并且会占用更大的芯片面积。Zen 5c则是针对可扩展性而优化,拥有相同的IPC和指令集但频率会较低,而且每个核心的L3缓存也较少,所以芯片面积也更小,单个内核面积会比Zen 5少25%,算上L3的话缩小比例更多。
AMD这次为面向移动处理器的Strix Point同时配备了Zen 5和Zen 5c两种内核,并通过简单的软件调度核心工作。由于Zen 5和Zen 5c拥有相同的IPC和特性,所以调度程序不太需要担心性能上的落差以及调度错误的问题,而且Zen 5和Zen 5c都支持SMT同步多线程,所以软件只需要考虑核心的效能和效率即可。
至于桌面端的Granite Ridge,也就是锐龙9000,AMD认为不需Zen 5c核心来扩展多线程性能,用两个Zen 5的CCD即可获得较好的多线程性能。

Zen 5增加了ISA指令集,包括MOVDIR/MOVD64B可跳过缓存直接移动4、8或64字节数据至存储;VP2INTERSECT和VNNI/VEK都是针对AVX512所增加的指令集,前者是AVX-512的向量对相交操作,后者则扩展AVX512指令到VEK编码;PREFETCHI是软件预取指令行到缓存层次结构。PMC虚拟化则是针对安全所增加的指令集。
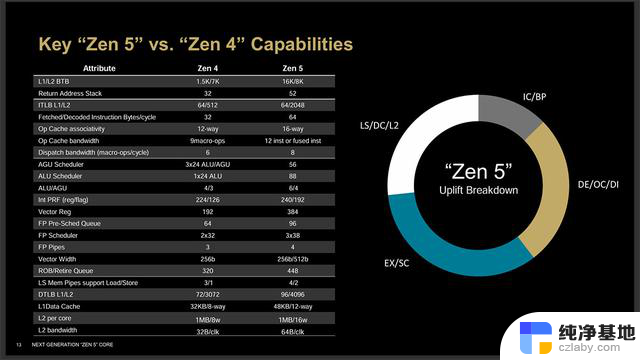
Zen 5对比Zen 4的改动汇总可见上表,Zen 5架构的性能提升主要由数据带宽、执行/退休、解码/指令缓存以及获取/分支预测这四大部分改进相互促进而成的,根据此前给出的数据,Zen 5的IPC较Zen 4平均提升了16%之多。
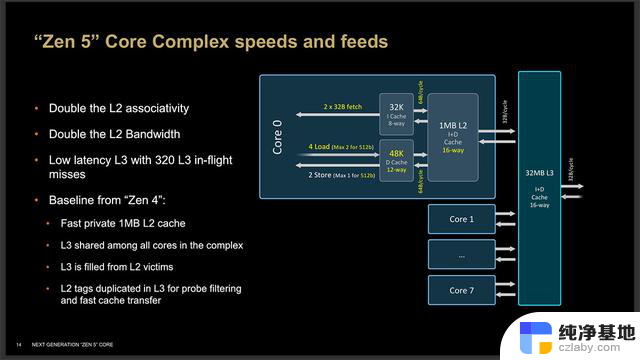
这是Zen 5 CCX的缓存结构图,大致结构和Zen 4差不多,L1缓存的变动在上面内核介绍时已经说了,L2缓存容量依然是1MB,但从8-Way增加到16-Way,这直接让L2缓存带宽翻倍,L3缓存的延迟有所降低。
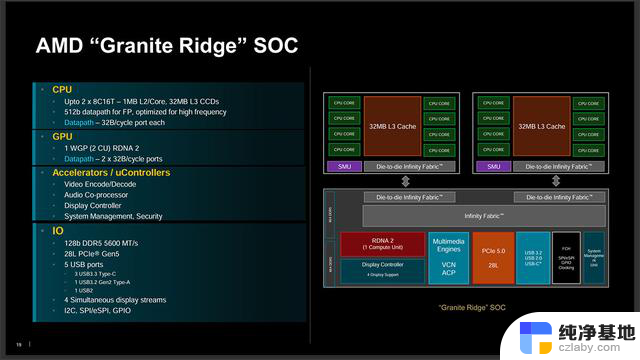
Granite Ridge其实没啥好说的,SoC结构和Zen 4的Raphael完全一样,继续使用上代的6nm IOD,可配备两个Zen 5 CCD,最多16核32线程,IOD支持128bit DDR5-5600内存,配备两个RDNA 2架构CU的核显,可提供4路显示输出,有28条PCIe 5.0,5个USB接口。
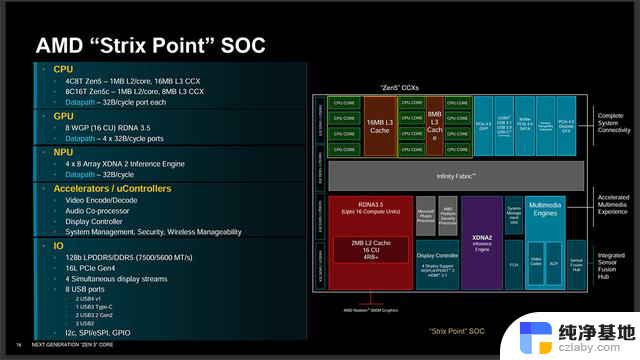
而面向移动端的Strix Point内部包含两组CCX,一个拥有4个Zen 5内核,拥有16MB L3缓存,而另一个则拥有8个Zen 5c内核,拥有8MB L3缓存,两者的缓存是相互独立的,需要通过SoC内部的IF总线通信。这设计就和此前的Phoenix 2很不一样,它拥有的2个Zen 4和4个Zen 4c是在同一个CCX内的,6个核心共享16MB L3缓存。
此外Strix Point还有一个配备16组RDNA 3.5架构CU的核显,一个4*8共32个AI引擎的XDNA 2架构NPU,IO方面,支持128bit LPDDR5-7500或DDR5-5600内存,提供16条PCIe 4.0通道,支持4路视频输出,一共可提供8个USB接口,包括两个USB4。
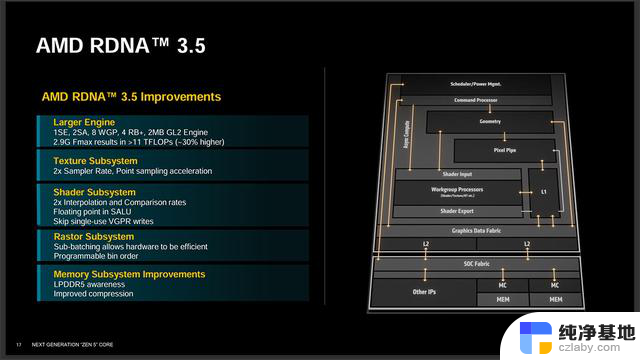
Radeon 890M核显有8组WGP,共16组CU,包含1024个流处理器、32个AI单元和16个光追单元、16个ROP,最高频率2.9GHz,FP32吞吐量超过11 TFLOP/s,同功率下较上代核显高出30%。
RDNA 3.5较原来的RDNA 3相比有两倍的纹理采样率和插值与比较速率,前者意味着GPU拥有前代的两倍性能,在游戏过程中纹理和图形的细节和清晰度得到增强,理论上有助于改善细节纹理,在高分辨率时更有冗余,而后者则可以更好地呈现高质量图形细节。
还引进了更先进的内存管理技术,提高了内存每bit的操作效能,降低了对LPDDR5内存访问频率,意味着读写更快,总体上也更节能,延长笔记本的电池续航力。
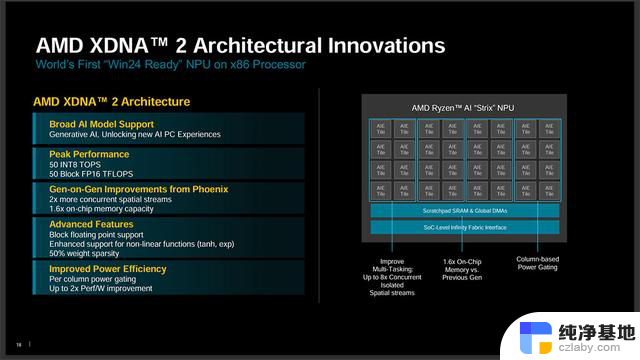
XDNA 2拥有32个AI引擎,每列拥有4个AI引擎,MAC数量较上代翻倍,缓存容量增加1.6倍,支持Block FP16块状浮点格式,支持非线性增强。NPU可根据任务的轻重程度以列为单位开启AI引擎,在轻任务下可以关闭部分核心,从而节约功耗,能效比初代提高了一倍。性能方面,XDNA 2可提供50 TOPS的AI算力,是上代的5倍。
除了即将上市的两款消费级处理器外,采用Zen 5内核的第五代EPYC也将会在今年下半年上市,目前的Zen 5 CCD以及锐龙AI 300将会采用台积电4nm工艺生产,而未来更紧凑、更节能的Zen 5c则会采用台积电3nm工艺。

总结一下,Zen 5带来了16%的IPC提升,改良重点包括平衡的跨核单/双线程指令和数据吞吐量;完整的512位浮点数据路径带来了更好的AVX512吞吐量,让AI性能提升;拥有各种高效能、高性能以及可扩展的解决方案。
没啥意外的话搭载Strix Point的笔记本会在7月28日发售,但Granite Ridge桌面处理器就延期了,AMD今天刚发出公告推迟锐龙9000系列处理器的发售日期,其中锐龙7 9700X和锐龙5 9600X推迟至8月8日,而锐龙9 9950X和9900X则延期至8月15日。