微软开源OmniParser纯视觉GUI智能体:GPT-4V秒懂屏幕截图最全攻略
传统的自动化方法通常依赖于解析 HTML 或视图层次结构,从而限制了其在非网络环境中的适用性。
而包括 GPT-4V 在内的现有的视觉语言模型(VLMs),并不擅长解读复杂 GUI 元素,导致动作定位不准确。
项目简介微软为了克服这些障碍,推出了 OmniParser,是一种纯视觉基础的工具,旨在填补当前屏幕解析技术中的空白。

该工具并不需要依赖额外的上下文数据,可以理解更复杂的图形用户界面(GUI),是智能 GUI 自动化领域的一项令人兴奋的进展。
OmniParser 结合可交互区域检测模型、图标描述模型和 OCR 模块等,不需要 HTML 标签或视图层次结构等显式基础数据,能够在桌面、移动设备和网页等上跨平台工作,提高用户界面的解析准确性。
OmniParser 除了识别屏幕上的元素,还能将这些元素转换成结构化的数据。
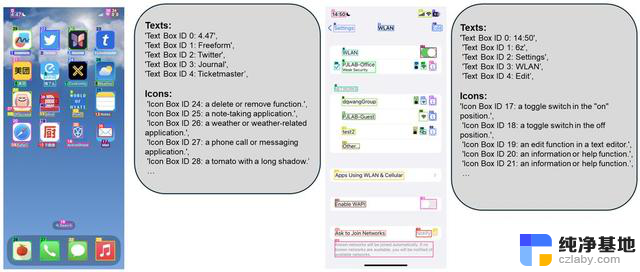
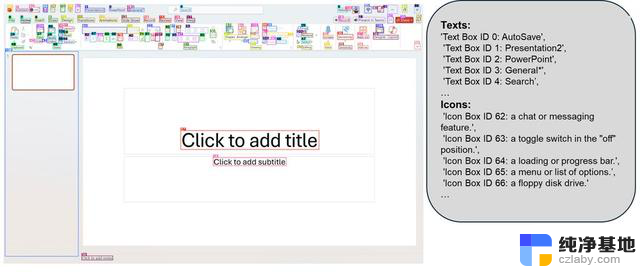
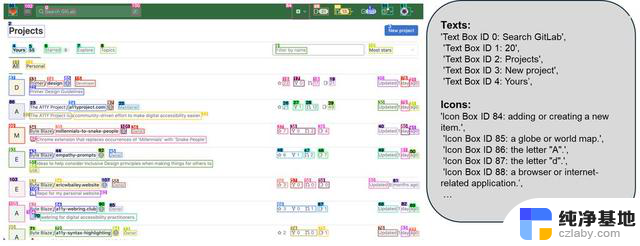
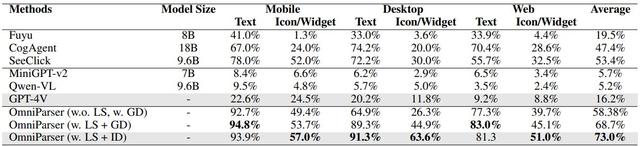
OmniParser 在多个基准测试中显示出优越的性能。例如,在 ScreenSpot 数据集中,其准确率提高了 73%,显著超越依赖 HTML 解析的模型。

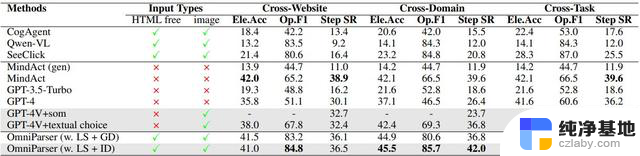
这一设计不仅能生成类似文档对象模型(DOM)的结构化表示,还能通过叠加边界框和功能标签来引导语言模型做出更准确的用户动作预测。
同时,GPT-4V 在使用 OmniParser 输出后,图标的正确标记率从 70.5% 提升至 93.8%。这些改进表明,OmniParser 能够有效解决当前 GUI 交互模型的根本缺陷。
OmniParser 的发布不仅拓宽了智能体的应用范围,也为开发者提供了一个强大的工具,助力创建更智能、更高效的用户界面驱动智能体。微软目前已在 Hugging Face 上发布 OmniParser,普及这一前沿技术。将进一步推动多模态 AI 的发展,特别是在无障碍、自动化和智能用户辅助等领域。
附上参考地址